
In Liza Pott’s Digital Rhetoric class at Michigan State University, we were assigned a “Tracing Digital Events” project, with the objective of learning “how to trace events in digital spaces, broadening [our]understanding of these technologies, participants, organizations, and genres” (Potts, WRA 415 assignment sheet). As relatively new scholars in digital rhetoric, we decided to use this assignment as an opportunity to trace conversations into which we might soon be entering, choosing to focus our analysis on last year’s 2013 Computers and Writing Conference held at Frostburg State University. This project helped us identify current trends in the Computers and Writing community, while simultaneously helping us think about how these trends are integrated and preserved in the digital platforms surrounding the conference itself. It also lead us to an analysis of tools used to interpret big data in digital spaces.
Since this Sweetland DRC blog carnival is focusing on “big” digital data, we want to discuss our process for analyzing the 5,600+ tweets coming out of the 2013 C&W Conference, which as Quinn Warnick pointed out via twitter, caused the conference tweets to trend in the U.S. While we analyzed conversations surrounding the conference in digital platforms such as the conference website and Facebook page, we want to share our analysis of the conference conversation happening using the #cwcon Twitter hashtag.

The Tools: For the purposes of analyzing a relatively large data set within a limited time, we used Linguistic Inquiry and Word (LIWC) to identify and quantify various word categories that could illustrate the different types of moves being made through conversations at the conference. LIWC users can use the LIWC dictionary to define words in one or more pre-determined categories and subcategories. For example, LIWC will categorize the word “cry” under the following: negative emotion, sadness, overall affect, verb, and past tense verb. It will then assign a percentage to each of the categories identified in the analysis. We should also note that LIWC allows users to create their own dictionaries in the program, allowing researchers to focus on language that develops from the data itself. However, both the LIWC dictionary and the user-generated dictionaries have some limitations in terms of providing contextual evidence to expand on linguistic categories.
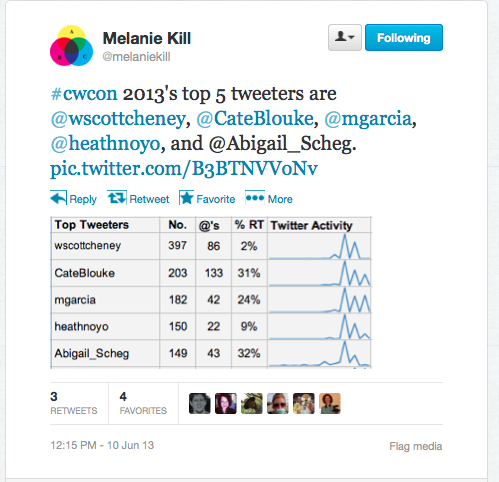
Following an initial linguistic analysis, we analyzed Twitter conversations archived and kindly shared with us by Melanie Kill, who used TAGSExplorer to collect all #cwcon tweets during the conference last year. We then used visualization tools such as Tagxedo to analyze the conversations about the conference more broadly.
The Analysis: We ran all 5,625 archived Tweets through LIWC’s default dictionary (after removing the symbols “@,” “#,” and “RT”). The following categories were identified by LIWC as most significant, representing at least 1% of the twitter conversations:
Pronouns (I, them, itself): 8.06%
Social (friends, family, humans, neighbor): 7.98%
Personal Pronouns (I, them, her): 5.04%
Positive Emotion (love, nice, sweet): 3.9%
Insight (think, know, consider): 2.38%
Achievement (earn, hero, win): 1.93%
Cause (because, effect, hence): 1.9%
Perceptual Processes (See, hear, feel): 1.73%
Leisure (chat, movie) 1.41%
Discrepancy (should, would, could): 1.21%
Negative Emotion (hurt, ugly, nasty, worried): 1.11%
So, what does this tell us? The high percentage of personal pronouns may be a reflection of the parameters of Twitter as a digital platform. Unlike Facebook, which provides a fixed space and a linear conversational record hosted by one anchor user, Twitter is a non-linear collection of statements or questions posted between individuals as an information network “without barriers” (about Twitter). Many of these individuals already know and “follow” each other in their professional and social interactions, and are anchored in this case by the #cwcon hashtag. The lack of a centralized conversation anchor (besides the hashtag), and personal relationships built before the conference may encourage users to tweet from a more individualized perspective thus using more personal pronouns.
The top three categories—pronouns, social, and personal pronouns—reflect the social nature of these conversations. Many of the tweets focus on supporting or lauding one another, expressing gratitude, or conveying personal emotion. Positive emotion greatly outweighed negative emotion. The instances where LIWC coded tweets as containing negative emotions reflect the stresses associated with an academic conference. Such words as “excited,” “great,” and “awesome,” reflected positive emotions, while words such as “stress,” “overwhelmed,” and “hard,” signaled the balance between work and leisure at play during the conference (and arguably in academia in general). While these tweets expressed an individual perspe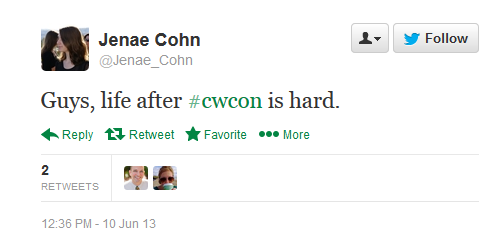 ctive, they were often re-tweeted, favorited, or responded to. In this way, tweets that expressed individual emotions became part of a collective experience as participants responded to each other. This tweet directly appeals to the group at large, and we can see that other tweeters interacted with it by retweeting. Retweeting, favoriting, and responding to tweets was one way in which the community interacted with each other, even turning tweets expressing personal emotion into a social interaction as part of the conversation at large.
ctive, they were often re-tweeted, favorited, or responded to. In this way, tweets that expressed individual emotions became part of a collective experience as participants responded to each other. This tweet directly appeals to the group at large, and we can see that other tweeters interacted with it by retweeting. Retweeting, favoriting, and responding to tweets was one way in which the community interacted with each other, even turning tweets expressing personal emotion into a social interaction as part of the conversation at large.
We can also see conversational moves in the many tweets concerned with reporting information. Many tweets draw attention to material presented in the conference sessions, simply restating the material or supporting what was discussed by the speakers. Some tweets pose questions based on this material, or link the information to their own areas of interest. These reporting tweets are where LIWC’s categories such as insight ,achievement, cause, perceptual processes and discrepancy can be seen. This is particularly the case during keynote presentations, where multiple conference attendees are often in the running to be the first to tweet interesting points made during the presentations. For example, check out the numerous references to Plato and video games captured by Michael Maune in this Storify of James Paul Gee’s keynote. (As of 2/2/2018 this Storify is now archived at the bottom of the page.)
Repeated tweets stemming from one presentation may help us identify what the community perceives as important, in this case linking to both ancient rhetorical tradition and more contemporary aspects of the field. We can then argue that Twitter provides a space for new names to enter the conversation, primarily by documenting the work of other established scholars. While #cwcon twitter conversations are not necessarily anchored around specific individuals, there is an emphasis on highlighted presentations and on the people who tweeted the most during the conference.
Issues with research methods and tools: While the linguistic analysis of #cwcon tweets provided a starting point for looking at disciplinary conversations in computers and writing, there are certainly many limitations to this type of research. As internet studies scholar, Nancy Baym suggests in “Data not Seen,” when analyzing big data on social media, “we need to remain keenly aware of the inherent multiplicity of meanings they collapse, the contexts in which they are embedded, and, perhaps most importantly, the depth of what they do not reveal.” This contextual layer was not always evident in LIWC’s analysis, which caused us to identify several potential discrepancies in the linguistic categorization:
Because of the informal way pe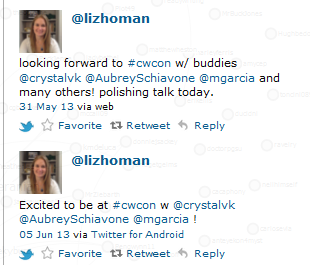 ople communicate on Twitter, including the use of abbreviations, some key words are missing and could not be coded by LIWC. Here, two tweets that should have triggered “personal pronoun” would go unnoticed because both the first and second tweet omit “I”. Pronouns occupied the highest category percentage at 8.06%, but due to the style of writing used in tweets, this percentage may actually be higher. Without context, tools used to sift through data can lead to misinterpretations of meaning. For example, LIWC coded this tweet as anxious, a word that is categorized as a negative emotion. However, the tweet expresses posit
ople communicate on Twitter, including the use of abbreviations, some key words are missing and could not be coded by LIWC. Here, two tweets that should have triggered “personal pronoun” would go unnoticed because both the first and second tweet omit “I”. Pronouns occupied the highest category percentage at 8.06%, but due to the style of writing used in tweets, this percentage may actually be higher. Without context, tools used to sift through data can lead to misinterpretations of meaning. For example, LIWC coded this tweet as anxious, a word that is categorized as a negative emotion. However, the tweet expresses posit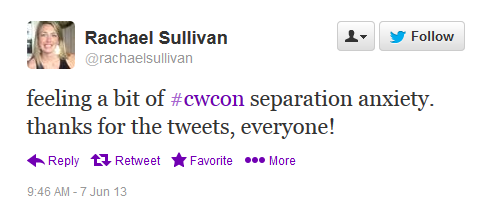 ive emotion about the conference. In a second instance, another tweeter uses the word anxiety as a joke while referring to something unrelated to the conference. Conversely, LIWC may recognize positive words that are actually being used to express negative emotion. In this tweet, the writer is expressing feelings of concern by using words generally thought to be positive such as hoping and victor. These coding discrepancies point to areas of concern in computational rhetoric, which seek to provide context for machine-coded data.
ive emotion about the conference. In a second instance, another tweeter uses the word anxiety as a joke while referring to something unrelated to the conference. Conversely, LIWC may recognize positive words that are actually being used to express negative emotion. In this tweet, the writer is expressing feelings of concern by using words generally thought to be positive such as hoping and victor. These coding discrepancies point to areas of concern in computational rhetoric, which seek to provide context for machine-coded data.
As a way to provide some context to our data analysis, we decided to look more closely at several examples after the initial LIWC categorization. We started by running the tweets through Tagxedo, a visualization tool that helped us look for words tweeted most often. As evidenced in this word cloud, “students” and “writing” were major concerns for tweeters that remained absent from LIWC’s analysis. In addition to LIWC’s categories, visualizing the tweets helped us see areas of the conversation and the conference program that may or may not be represented on Twitter. For example, presentations about multimodality, learning, and students seemed to have more representation than issues of gender, language, and race, which appear much smaller in Tagxedo’s visual. Looking at LIWC’s categories in conjunction with Tagxedo’s visualization helped us contextualize the Twitter conversations, though there is certainly much more that could be done to represent the conversations more accurately.

Why Does this analysis matter? After the conference is over, tweets are one of the most tangible records we have of the conversations participants engaged in. Many people who do not have access to physical conferences participate through online components, often reading and even blogging about conversations happening on Twitter. While Computers and Writing has an online conference that is archived, and while participants are increasingly sharing their conference resources online, it’s important to think about the values being represented through all digital interactions. What is said on Twitter says something about the study of Computers and Writing. It says something about what is really being discussed by the community of scholars in this field, despite what is listed on the schedule. An analysis of these conversations brings greater visibility to areas of interest while helping us think about areas that might be neglected, and it may help us represent our disciplinary values more effectively. Using the record of our own conversation may help guide the community to areas that need more attention, and big data analysis with contextual additions may be only a small step in this direction.
–A big thanks to Liza Potts at MSU for helping us with this project and post, to Melanie Kill at U of Maryland for sharing her #cwcon twitter data, and Lindsay Neuberger at the University of Central Florida for help running our data through LIWC.
Storify of James Paul Gee’s Keynote (some tweet images are missing and replaced with void links due to the Storify archiving process):
Comin' soon to #cwcon – Q&A: Jim Gee on The Right Role of Digital Games in the Classroom http://t.co/2GDHzN67u8 via @zite
— HarlotOfTheArts (@HarlotTweets) June 5, 2013
#cwcon Really looking forward to Gee. http://t.co/xXBWs6oAWX
— Harley Ferris (@harleyferris) June 7, 2013
Standing next to your sociolinguistics crush at #cwcon #win #gee pic.twitter.com/7a3xKne61g
— Jennifer Buckner, PhD (@rhetorjjb) June 7, 2013
Eating lunch under Plato's gaze as Gee is introduced. #happy #cwcon
— Dr. Karen LaBonté (@klbz) June 7, 2013
http://twitter.com/kellerej/status/343032513096196096
James Paul Gee's keynote address: colleges are profoundly broken. #cwcon #dangitworld
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
Gee: "We're impervious to evidence." #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
Fascinating to hear James Paul Gee starting his talk on maker movement with framework of current extremes of inequality. #cwcon
— Anastasia Salter (@AnaSalter) June 7, 2013
http://twitter.com/heathnoyo/status/343033460878880769
Gee cites Plato: "writing is inert." "Plato would have loved video games!" #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
Gee – Plato would have loved video games. It talks back2 u #cwcon
— HarlotOfTheArts (@HarlotTweets) June 7, 2013
James Paul Gee keynote #cwcon: Plato complains writing can't talk back… is inert, not interactive. "Plato would have loved video games."
— Dennis Jerz (@DennisJerz) June 7, 2013
Gee: I think that Plato would have liked video games. #cwcon
— Emi Stuemke (@Emigurumi) June 7, 2013
Gee: "Plato would have loved video games" #cwcon
— Leigh Gruwell (@leighthinks) June 7, 2013
Gee: Plato would have loved video games…they talk back. #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
http://twitter.com/heathnoyo/status/343033783773171712
http://twitter.com/johnmjones/status/343033872172343297
Gee on interactivity: Plato would've liked video games #cwcon
— Jennifer Sano-Franchini (@jsanofranchini) June 7, 2013
Writing as we teach it is not interactive. #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Nobody knows how to read or write unless they can claim an understanding of the world.- Gee #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
Jim Gee keynote on gaming as an interactive writing practice. He argues that thinking is like running a simulation. #cwcon
— Merideth Garcia (@mgarcia) June 7, 2013
#cwcon #kn1 James Paul Gee tells a bunch of writing teachers about Plato and Freire. Video games talk back, like the slave?
— Mike Edwards (@preterite) June 7, 2013
Humans think well if they can mentally simulate actions based on experience. #cwcon #gee
— Dennis Jerz (@DennisJerz) June 7, 2013
Absolutely love that Gee just called out academic writing as gobbledygook. #cwcon
— Cate Blouke (@CateBlouke) June 7, 2013
Gee: Humans think well if they have an action to take. #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
School is set up as a classic example of how to make people look stupid. #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Gee – also talks about how school is designed to make people look stupid vs. pop culture designed to make them look smart #cwcon so true!
— Cate Blouke (@CateBlouke) June 7, 2013
"School is set up to make people look stupid. " Gee #cwcon
— Dr. Karen LaBonté (@klbz) June 7, 2013
“School is set up in a way that is meant to make a lot of people look stupid” – James Paul Gee #cwcon #fb
— Michael J. Faris (@sisypheantask) June 7, 2013
http://twitter.com/johnmjones/status/343034974955528195
"Prototypical human beings – when they give a damn, they're smart, when they don't, they're stupid." ~Jim Gee #cwcon
— Merideth Garcia (@mgarcia) June 7, 2013
"School is set up as a classic example of how to make people look stupid" Gee #cwcon #KN1
— Laura Gonzales (@gonzlaur) June 7, 2013
Gee: When human beings give a damn they're smart, when they don't they're stupid. #cwcon
— Jennifer Sano-Franchini (@jsanofranchini) June 7, 2013
James Paul Gee at #cwcon: school is,set up to make people look stupid; pop culture is set up to make them look smart
— Kate M Maddalena (@KateMadd) June 7, 2013
http://twitter.com/jenmcunningham/status/343035119243755521
http://twitter.com/LilianMina/status/343035192774127616
http://twitter.com/johnmjones/status/343035212831281152
James Paul Gee says when they give a damn they're smart, if not they're stupid #cwcon #kn1
— Hannah Bellwoar (@hpbellwoar) June 7, 2013
#cwcon paraphrasing Gee when people care about a subject they can be really smart when they don't they can be really stupid.
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Gee's Barsalou quote reminds me of Neal Stephenson's argument in Anathem #cwcon
— BenM (@benmiller314) June 7, 2013
Gee is talking about the specialist language of Yu-Gi-Oh, and I am suddenly missing Magic: the Gathering. Summoning sickness anyone? #cwcon
— Anastasia Salter (@AnaSalter) June 7, 2013
Start w/action, not language (Gee) #cwcon
— Jennifer Sano-Franchini (@jsanofranchini) June 7, 2013
Card gaming as an embodied multimodal practice. Jim Gee calls it "situated meaning." #cwcon
— Merideth Garcia (@mgarcia) June 7, 2013
#cwcon Gee is my hero
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Gee: Start with action, not with text as written language. #cwcon
— Amber Buck (@ambi24) June 7, 2013
James Gee: YuGiOh! Card game proves that young kids can become proficient in non-standard, situated, technical languages. #cwcon
— Kate M Maddalena (@KateMadd) June 7, 2013
#cwcon #kn1 Gee: teaching the Yu-Gi-Oh way = teaching multimodally.
— Mike Edwards (@preterite) June 7, 2013
Language is hard to learn when it is not situated.- Gee #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
James Paul Gee: key to literacy ed is to map action to words/language. #cwcon
— Elizabeth Davis (@drelizabethd) June 7, 2013
Situated meaning is "to a word you can assign an image action or meaning" @Gee #cwcon
— joy robinson (@njoying) June 7, 2013
Gee: when you understand language in a situated way, it's not hard. #cwcon
— Patrick W. Berry (@pb112233) June 7, 2013
Gee: Yu-Gi-Oh! says that if you have trouble I'll give you more tasks, more actions, more stories. #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
Gee- when you understand language in a situated way, there is no "hard language" #cwcon true of academic writing AND video game instructions
— Cate Blouke (@CateBlouke) June 7, 2013
Gee re: language It's hard when you have no embodied situated visuals. This is why I listen better when I'm knitting #kn1 #cwcon
— Hannah Bellwoar (@hpbellwoar) June 7, 2013
http://twitter.com/aristotlejulep/status/343036664056254464
#cwcon Gee argues for learning by giving people experiences. Concrete images and experiences. The experience of the game creates meaning.
— Jim Kalmbach (@jimkalmbach) June 7, 2013
#cwcon #kn1 wondering: how could Gee’s argument re multimodal learning be applied to tech comm?
— Mike Edwards (@preterite) June 7, 2013
#gee read a game manual that seemed impenetrable. He then played the game, and returned to the manual — which seemed perfectly easy. #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
James Paul Gee said (technical, academic) language is only hard if we don't have situated, embodied experience to process it. #preach #cwcon
— Allison Hitt (@ahhitt) June 7, 2013
Gee has already got me thinking about playing Twitter games in class. #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
Gee says school is like giving kids the manuals to games without giving them the games. It's worthless w/out the game. #cwcon
— Cate Blouke (@CateBlouke) June 7, 2013
School is like giving kids 10 game manuals but no games (Gee) #cwcon
— Jennifer Sano-Franchini (@jsanofranchini) June 7, 2013
#cwcon Gee school is like giving students games manuals without the games
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Schooling gives kids manuals about games they don't get to play. #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
#cwcon #kn1 I’m teaching 400-level science & tech writing course in 2014. What would Gee’s pedagogy look like in such a course?
— Mike Edwards (@preterite) June 7, 2013
http://twitter.com/LilianMina/status/343037404631928834
http://twitter.com/johnmjones/status/343037422478692352
http://twitter.com/elmar_hashi/status/343037477319225345
School: asking Ss to read the manual w/o letting them play the game. They know nothing about the scenario, and we blame them. —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Gee points out how Video games put us not into a textbook but into a world. #cwcon
— Cate Blouke (@CateBlouke) June 7, 2013
http://twitter.com/aristotlejulep/status/343037551512268800
#cwcon gee: humans are smart only when they have a problem to solve that they care about.
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Wow. Yikes. Gee: school is trying to teach about a world kids don't live in, to be a manual for a game they don't play. #cwcon #kn1
— Kate M Maddalena (@KateMadd) June 7, 2013
http://twitter.com/adamstrantz/status/343037933110046721
Gee describes experiment about making people simulating a life of poverty in The Sims. #cwcon
— Michael Widner (@mwidner) June 7, 2013
Having not played yu-gi-oh or the 2nd game Gee mentioned, I'm struck by the transferability of genre knowledge. Still very readable. #cwcon
— BenM (@benmiller314) June 7, 2013
Gee implicitly makes clear the need to more deeply interrogate the needs and concerns of students not just as students but as ppl #cwcon
— Jennifer Sano-Franchini (@jsanofranchini) June 7, 2013
"Living a life of poverty is not fun…as many of you [GTAs] will soon find out bcs downward mobility is easier than upward." —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Gee: when a game is good communities form around learning more about the game. Can we design edu like this? #cwcon
— Dr. Amanda Licastro (@amandalicastro) June 7, 2013
#cwcon great parallels between Gee's maker movement and Axel Bruns' produsage. Somewhere beyond production/consumption dichotomy.
— Tom Skeen (@materealizing) June 7, 2013
"School is set up to make people look stupid," J.P. Gee at #cwcon
— Emily Simnitt (@EmilySimnitt) June 7, 2013
Writing about living a life of poverty in The Sims — students create own learning and mentor each other #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Gee: Students design their own learning. #cwcon
— Michelle Sidler (@michellesidler) June 7, 2013
@ashleyrkelly James Gee is using FoldIt as an example in #kn1 at #cwcon!!!
— Kate M Maddalena (@KateMadd) June 7, 2013
Even better, games in which players design their own learning environments. Again, transfer to higher ed? #gee #keynote #cwcon
— Dr. Amanda Licastro (@amandalicastro) June 7, 2013
Gee relates example of a gamer's guild producing results for protein folding that compete with the quality of a Ph.D.'s. #cwcon
— Michael Widner (@mwidner) June 7, 2013
#cwcon keynote #1: James Paul Gee begins by talking about inequality and/in education.
— Patti Poblete (@voleuseCK) June 7, 2013
Gee: "Plato would have loved video games." #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Gee: "Humans think well when they have an action they want to take." #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Gee is talking about playing Yu-gi-oh. Huzzah! #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Teach the Yu-Gi-Oh way. Or should we say the Yu-Gee-Oh way? #gee #cwcon #funwithlanguage
— L Garcia-DuPlain (@LGDuPlain) June 7, 2013
Gee: Gain literacy through playing/doing, not reading instructions. #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Gee: Yu-gi-oh proves Friere is right because it provides situated meaning–defining words through image/experience, not more words. #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Fold It and Galaxy Zoo — games that rely on human pattern recognition and "the death of experts" — success w/o credentials #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Wow, Gee isn’t just saying great stuff. He’s also a great presenter. #cwcon
— Jennifer Veltsos (@jenveltsos) June 7, 2013
Crowdsourced advertising competitions revealed that everyday people could make better ads than million dollar companies. #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Gee: The death of experts: today anybody 7 years old to 80 years old can do whatever they want to do without a credential #cwcon
— Emily Simnitt (@EmilySimnitt) June 7, 2013
http://twitter.com/Abigail_Scheg/status/343039947818815488
Many of Gee's critiques of education as it exists today resonant strongly with points @CathyNDavidson makes. #cwcon
— Michael Widner (@mwidner) June 7, 2013
Gee: brains are built for goal-based action. Humans are plug-and-play devices. #keynote #cwcon
— Dr. Amanda Licastro (@amandalicastro) June 7, 2013
Gee: Human brains aren't meant to think on their own–we have to have good tools and collaborate with other people #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Gee gems: "Brains are built for goal-based action. Humans are plug-and-play devices" #cwcon
— Emily Simnitt (@EmilySimnitt) June 7, 2013
Humans are plug and play devices (Gee) #cwcon
— janicewalker (@janicewalker) June 7, 2013
"Brains are built for goal-based action. Humans are plug and play devices."- Gee #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
“64% of Americans don’t believe in Evolution, but they still get a flu shot.” —Gee #perspective #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Gee we're built to be smart when we build tools and use them collaboratively to engage in action #kn1 #cwcon
— Hannah Bellwoar (@hpbellwoar) June 7, 2013
Gee – what was language if not a tool to allow people to collaborate and build things together? #cwcon
— Cate Blouke (@CateBlouke) June 7, 2013
http://twitter.com/LilianMina/status/343040282159357953
http://twitter.com/johnmjones/status/343040285804212225
#cwcon Gee: brains are built for goal based action. Humans are plug and play devices. Yes.
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Gee: We ban the tools that students have learned to use for thinking. #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Facepalm at banning Moby Dick game because of the word dick #cwcon #gee #lolwut
— Dr. v is for வலி 📚 (@vymanivannan) June 7, 2013
Gee: "collaboration in most schools is called cheating." #cwcon
— Dustin Edwards (@edwardsdusty) June 7, 2013
#cwcon #kn1 starting to get a handle on Gee’s style: he’s going for aphoristic?
— Mike Edwards (@preterite) June 7, 2013
Gee says you can't run an instance with five priests. (But…you could run one with three priests, I think.) #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
http://twitter.com/Abigail_Scheg/status/343040885736480769
http://twitter.com/KBlakespeare/status/343041705802596354
Gee: "Humans using plug and play devices." Sounds like Latour's plugins. Never thought I'd put them together. #cwcon
— Michelle Sidler (@michellesidler) June 7, 2013
Gee: "Here's a man we all hate: Alan Greenspan." LOL #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
#cwcon Gee compares mods by WoW players to PhDs' abstract theories: both require lots of experience to be useful and legible.
— Amanda Wall (@_AmandaWall) June 7, 2013
Gee: The world is now so complex that it takes a team to understand. No one expert can figure it out. #cwcon
— Michael Widner (@mwidner) June 7, 2013
Gee: it takes a team, like a world of Warcraft team, to understand our world #cwcon
— Emi Stuemke (@Emigurumi) June 7, 2013
#cwcon experts who know a lot about one thing are truly dangerous. We need diverse teams Gee
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Gee: Experts who only know a lot about one thing are dangerous. #cwcon
— Dr. Erin Clark Frost (@ErinAFrost) June 7, 2013
Gee: it takes a team to understand the complexity of the world #cwcon
— joy robinson (@njoying) June 7, 2013
Gee: Experts who know one thing really well are dangerous because the woeld is so complex. #cwcon
— Dr. Karen LaBonté (@klbz) June 7, 2013
Gee: we don't need experts, we need flexible teams. Understand all roles. #keynote #cwcon
— Dr. Amanda Licastro (@amandalicastro) June 7, 2013
Gee: takes a team to solve problems and understand systems. How do we apply this to our classrooms? #cwcon
— Amber Buck (@ambi24) June 7, 2013
#cwcon Itching to work on my fall syllabus rn to take into account what I'm hearing from Gee.
— Amanda Wall (@_AmandaWall) June 7, 2013
Gee: It takes a team. Minds. #cwcon
— L Garcia-DuPlain (@LGDuPlain) June 7, 2013
World so complex/networked it takes a team, not a single expert, to deal – Gee. Gotta think networks, I tell ya. #cwcon
— Elizabeth Davis (@drelizabethd) June 7, 2013
Gee: The face of expertise in the future is a 15yo fanfic writer who got better through mentoring and practice. #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
#cwcon #kn1 Gee: lone experts=dangerous; need teams of them. Blames Greenspan for 2008, then blames “moral hazard.” Banker teams did ‘08.
— Mike Edwards (@preterite) June 7, 2013
15yo Sims graphic novelist with huge following & adoring fans. Face of new expertise. Pop culture, not school, is dignifying. #gee #cwcon
— Dennis Jerz (@DennisJerz) June 7, 2013
Popular culture, not school, gives kids their senses of dignity and self-worth. —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
@briancroxall @johnmjones what a coincidence! James Paul Gee is lunch #keynote at #cwcon in Frostburg. Good talk so far.
— Dr. Amanda Licastro (@amandalicastro) June 7, 2013
Gee: Kids are finding a place to express and know in the culture outside of school #cwcon
— Emily Simnitt (@EmilySimnitt) June 7, 2013
#cwcon gee: it is popular culture not school that is giving most students their sense of dignity.
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Gee: drive/teamwork/mentoring/pop culture — all means to learn about plagiarism #cwcon
— Dustin Edwards (@edwardsdusty) June 7, 2013
Gee answering the question we focused on in my dig journ class all semester re trained v. citizen journalists: it takes a team. #cwcon
— Amber Buck (@ambi24) June 7, 2013
Gee: the Maker Movement is self-protection from dangerous "experts", self-worth found in making. #cwcon
— Michael Widner (@mwidner) June 7, 2013
#cwcon gee self worth not explotation
— Jim Kalmbach (@jimkalmbach) June 7, 2013
We've been trying to teach this old technology—you know, writing—since 16th century, & we haven't succeeded yet. Get on it. —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
http://twitter.com/johnmjones/status/343043838182580224
Gee: teach people to be producers, not consumers, to lead lives of dignity and respect. #cwcon
— Michael Widner (@mwidner) June 7, 2013
#cwcon gee what a great talk
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Focus in production and impact, and we will change society -Gee #cwcon #keynote
— Angela (@angela757) June 7, 2013
Gee asks what are the skills in a fast changing world going to look like? #cwcon
— Hannah Bellwoar (@hpbellwoar) June 7, 2013
Hey #thatcamp folks, you might like some of the discussion of Gee’s keynote in the #cwcon stream. Wish I could be at both!
— Anastasia Salter (@AnaSalter) June 7, 2013
What are the skills in a fast changing world going to look like? (Gee) #cwcon
— janicewalker (@janicewalker) June 7, 2013
Sustainability over – now we have to think about resiliance instead – Gee. #cwcon
— Elizabeth Davis (@drelizabethd) June 7, 2013
Sustainability is no longer what's at stake: resiliency (and flexibility is). – Gee #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
Gee is pro-Makers All. Take note, Boilermakers. #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
twitter blowin up all through this keynote, but when gee asks for questions or comments? crickets… #cwcon
— matt.gomes (@mathewjgomes) June 7, 2013
Gee: make people resilient, prepare them to innovate and think through complex systems, be meta-aware. Learning for 21st century. #cwcon
— Michael Widner (@mwidner) June 7, 2013
#cwcon gee: self protection from experts: maker, collective intelligence and action
— Jim Kalmbach (@jimkalmbach) June 7, 2013
Let's all tweet it. Gee: what they really need in NY is a snorkel. #cwcon
— Emi Stuemke (@Emigurumi) June 7, 2013
Gee: divide between arts and humanities and sciences just “bullshit.” #cwcon
— Anastasia Salter (@AnaSalter) June 7, 2013
#cwcon #gee From sustainability to resilience. Change with change, or be dupes to the system. Humanities/tech divide is BS.
— Dennis Jerz (@DennisJerz) June 7, 2013
http://twitter.com/Abigail_Scheg/status/343044967704436739
http://twitter.com/amelish/status/343044977850449920
Gee: The divide between the humanities and the sciences is, and I quote, "bullshit." #cwcon
— Leigh Gruwell (@leighthinks) June 7, 2013
“What they really need in New York is a snorkel. You know, bcs of global warming.” —Gee / We need them outside in Frostburg's fog. #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Gee: Divide between arts and sciences is a joke with serious consequences. #cwcon
— Dr. Erin Clark Frost (@ErinAFrost) June 7, 2013
“Wall Street is what you get when everyone majors in Business. They should all be sentenced to 10 years of humanities.” —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Heh. Gee: "STEM people should be sentenced to 10 years of humanities." #cwcon
— wscottcheney (@wscottcheney) June 7, 2013
Gee – humanities hopefully teaches us to think deeply about human relationships and ethics. Economic collapse as a failure of ethics. #cwcon
— Cate Blouke (@CateBlouke) June 7, 2013
Gee's talk reminds me of @neilhimself's commencement address http://t.co/b12ZO0QfRh… Make Good Art #cwcon
— Merideth Garcia (@mgarcia) June 7, 2013
Wall Street should be sentenced to 10 years of humanities. Ethical breakdown caused 2008 economic collapse. #cwcon #gee
— Dennis Jerz (@DennisJerz) June 7, 2013
@tekla_h @timlockridge #cwcon The question is whether we should be teaching our discipline-specific language to students. Gee says no.
— Amanda Wall (@_AmandaWall) June 7, 2013
#cwcon gee says I think instead of sustainability think about resilience
— Jim Kalmbach (@jimkalmbach) June 7, 2013
@timlockridge yes. It had to be both. The guild, to use Gee's metaphor, need to talk together as well as w others. #cwcon
— Amber Buck (@ambi24) June 7, 2013
“Wall Street is what you get when everyone majors in Business. They should all be sentenced to 10 years of humanities.” —Gee #cwcon”
— iSophist 🚢 🤖🏛️ | Rhetoric & Prompt Engineering (@LanceElyot) June 7, 2013
James Paul Gee’s #cwcon keynote made me feel good about what I do in the classroom and reminded me how much I still have to learn.
— Quinn Warnick (@warnick) June 7, 2013
Gee's best line: Wall Street should be sentenced to 10 years of the humanities. #cwcon
— Amber Buck (@ambi24) June 7, 2013
What does it mean to be a learner in the 21st century?- Gee #THEquestion #cwcon
— Dr. Jenae Cohn (@jenaecohn@sotl.social) (@Jenae_Cohn) June 7, 2013
Harvard could change its curriculum to waterboarding all students. People would still buy the status. #cwcon #gee
— Dennis Jerz (@DennisJerz) June 7, 2013
Gee: "Imagine a college [filled with]affinity spaces." #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
Gee: colleges retooled as affinity spaces to solve problems #cwcon
— Dustin Edwards (@edwardsdusty) June 7, 2013
#gee Self-protection from experts = maker, action, collective intelligence = cant help but think of 4chan #cwcon #yesiamaonetrickpony
— Dr. v is for வலி 📚 (@vymanivannan) June 7, 2013
Gee says we haven't had free markets for decades. Maker Movement may change this…? We hope #cwcon #kn1
— Liz Homan (@lizhoman) June 7, 2013
Gee: Space for the movement of everyday experts #cwcon
— Emi Stuemke (@Emigurumi) June 7, 2013
http://twitter.com/LilianMina/status/343046625847037952
Gee: There are no remedial writers, only people who have the manual, but not the game. #cwcon
— Michael Widner (@mwidner) June 7, 2013
Reading the tweets coming out of John Paul Gee's keynote at #cwcon make hopeful for the future! http://t.co/XfiUK4knq0
— Amanda Barton (@cresida) June 7, 2013
“There aren't any remedial writers. There are just people who can't play the game and weren't given the manual.” —Gee #cwcon
— Chris Friend (@chris_friend) June 7, 2013
Yes, he is throwing serious rhetorical shade. "@Abigail_Scheg: Gee is hilarious. Loving this keynote. #cwcon"
— Dr. LaToya L. Sawyer (@DrLaToyaLydia) June 7, 2013
http://twitter.com/heathnoyo/status/343047008749223938
#cwcon gee there are remedial writers there are only people who try to play the game by only read the manual
— Jim Kalmbach (@jimkalmbach) June 7, 2013
@njoying: Gee: Production the 21st century skill.#cwcon
— joy robinson (@njoying) June 7, 2013
Oh and my last three tweets are a direct response to what you all have quoted from Gee's #cwcon address. Must have sounded better live.
— Dr. Catherine Prendergast (@cjp_still) June 7, 2013
The writing classroom should be the place of production. Great comment for Gee to end his talk. Thank you! #cwcon
— Beth Bensen (@ebensen65) June 7, 2013
The moment where you see "Gee" on your other timelines for Computers and Writing 2013 (#cwcon) and you automatically think 소녀시대.
— Rob (@Tellerius) June 7, 2013
http://twitter.com/elmar_hashi/status/343048118473990145
I'd say that the tweets from Gee's #cwcon left me feeling mansplained, but it seems very little was really "sprained."
— Dr. Catherine Prendergast (@cjp_still) June 7, 2013
We need to get rid of notion of remedial writers. There are writers who don't play the game by our rules. #Gee #cwcon
— Dr. LaToya L. Sawyer (@DrLaToyaLydia) June 7, 2013
Gonna mod that quote, @chris_friend: Gee said they *haven't* (yet) played the game, and that a manual is worthless until they have. #cwcon
— BenM (@benmiller314) June 7, 2013
J.Paul Gee just delivered an awesome keynot on digital literacy, games and learning! Exciting stuff! #cwcon
— datacanlas (@datacanlas) June 7, 2013
http://twitter.com/johnmjones/status/343063450894876673
Kuhn: Pedagogy and advertising should be separate things. (sometimes we don't make those distinct. C/F Gee's keynote, at points.) #c9 #cwcon
— Patti Poblete (@voleuseCK) June 7, 2013
http://twitter.com/GrahamMOliver/status/343066161040216064
http://twitter.com/Vieregge/status/343066250819289088
@dbfuturist42 I enjoyed JP Gee; I know not everyone does! #cwcon
— Shelley Rodrigo (@rrodrigo) June 7, 2013
@lehua14 sharing study participant video that aligns w/JP Gee's comment about people producing to have an identity/voice #cwcon #d4
— Shelley Rodrigo (@rrodrigo) June 7, 2013
anyone know if the full text of Gee's keynote is available? #cwcon
— Steph Ceraso (@stephceraso) June 7, 2013
@stephceraso Dunno. But my guess is that if a video is available it'll end up at http://t.co/YvDacUzXi3. (@iamdan?) #cwcon
— Kyle Stedman (@kstedman) June 7, 2013
The genre of the profile as active, ethnography (enacted), transmedial. Works w Gee's idea of student as maker #F9 #cwcon
— Dr. Karen LaBonté (@klbz) June 8, 2013
http://twitter.com/adventuresinphd/status/343452965916508160
1 Comment
Pingback: How I Use Twitter at Conferences | Transmedia Me